-
페치 조인의 한계과 극복(요약 ver.)개발/JPA 2023. 7. 25. 15:14
JPA를 사용할 때 fetchType은 기본적으로 LAZY로 지정하고 시작한다. EAGER는 최적화가 제한되기 때문에 선택지에서 아예 제외하도록 하자. OneToOne, ManyToOne(이하 XxxToOne)은 조인을 해도 결과 데이터 수가 늘어나지 않는다. 일대다 조인을 하면 다(N)에 맞춰서 데이터가 늘어나게 된다(데이터 뻥튀기). 팀과 멤버가 일대다 관계라고 했을 때, 팀과 멤버를 조인하게 되면 멤버 데이터에 팀이 합쳐진 데이터가 출력된다.
엔티티를 로딩할 때 XxxToOne 데이터는 페치 조인으로 데이터를 Query 한 번으로 가져와 성능 최적화를 할 수 있지만, 문제는 컬렉션이다. 페치 조인을 하게 되면 그 뻥튀기 된 데이터가 전부 조회된다. SQL 단계에서 당연히 distinct도 적용 안 되며 페이징도 되지 않는다. 만약 이 데이터들을 다 가져와서 메모리에서 하는 페이징은 너무 끔찍해서 로그에 경고도 찍어준다.

주문 엔티티에 주문 아이템이 여러 개 있다고 가정해보자. 실제로 우리가 커머셜에서 상품을 주문할 때 한 주문에 여러가지 상품을 넣을 수 있는 것과 마찬가지로. 이 경우 아무런 최적화를 하지 않으면 반복문에서 여러 개의 상품을 로딩해올 때 매번 조회 Query가 발생하기 때문에 N+1 문제가 생긴다. N+1 문제를 1+1로 해결해주는 방법이 batch fetch다.
프록시초 초기화된 객체가 반복문을 돌 때마다 Query를 발생시키는 N+1문제를 해결하는 방법은, 반복문을 한 번 돌 때 설정에서 정해준 숫자만큼 데이터를 한 번에 로딩하는 것이다. 그러고 나면 다음 반복 때부터는 영속성 컨텍스트에서 데이터를 가져오면 되기 때문에 DB를 조회하지 않아도 된다. 반복문이 Batch 사이즈를 초과하면(가령 100이라면), 그다음 반복 때(101번째) 정해진 크기 만큼 데이터를 다시 로딩한다. 하이버네이트 5에서는 in query를 통해 데이터를 가져왔었는데, 하이버네이트6부터는 array_contains 함수를 사용한다.
> 하이버네이트5

> 하이버네이트6
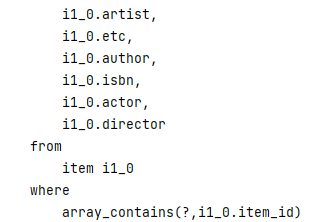
-> 둘의 결과는 완전히 동일하지만 성능 최적화 관점에선 다르다. 데이터베이스는 이미 실행된 SQL을 캐싱하는데 in query를 사용할 때는 바인딩해야 할 데이터의 수가 동적으로 변하기 때문에 캐시 미스가 날 수 있다. array_contains의 첫 번째 인자는 배열이므로 바인딩 데이터의 수가 변하지 않는다. SQL 구문이 동적으로 늘어나지 않으면 캐싱해놓은 SQL을 쓸 수 있으니 성능 상의 이점이 있다.
batch 설정은 @BatchSize 애노테이션을 컬렉션 필드 혹은 단일 엔티티는 엔티티 클래스에 적용하거나 전역으로 적용할 때는 application.properties나 yml 파일에 옵션을 넣으면 된다. yml 기준으로 다음과 같다.
spring: jpa: properties: hibernate: default_batch_fetch_size: 100'개발 > JPA' 카테고리의 다른 글
Update (0) 2024.03.03 스프링부트 3.1.2 Querydsl 설정 (0) 2023.08.02 MVCC=TRUE (0) 2023.07.18 일대다 연관관계를 지양하자 (0) 2023.07.18 영속성 전이와 고아 객체 (0) 2023.07.13